



The proposed AI-based diet recommendation method utilizes a novel deep generative network architecture to provide personalized meal plans to users based on their profile. More specifically, a variational autoencoder network processes the input, which is a vector that contains individual information (e.g., weight, height, age, etc.). The produced feature representation lies in a latent space, in which the input information can be modelled in an optimal way and capture meaningful and informative features about the user’s dietary requirements. Subsequently, a recurrent neural network is utilized to generate sequences of meals and construct the weekly meal plan. At the last stage, the generated meal plans are fed to an optimizer that adjusts the meal quantities to ensure that the energy and nutrients align with the user’s requirements and a final weekly meal plan is formulated. Additionally, ChatGPT10, a powerful language model developed by OpenAI, is adopted in order to expand the original meal database and enhance meal recommendations. The overview of this method is depicted in Fig. 1, while the main components of the proposed architecture are described in detail in the following subsections.
The user profile comprises the only input to the proposed AI-based diet recommendation method and it is crucial for the creation of valid personalized nutritional advice that adheres to user’s needs and nutritional guidelines. The user profile holds important anthropometric measurements and information on the physical activity status and medical condition of a user. More specifically, the profile consists of the weight, the height, the basal metabolic rate (BMR), the age, the body mass index (BMI), the targeted energy intake, the physical activity level (PAL) and the existence or not of cardiovascular disease, type-2 diabetes (T2D) and iron deficiency. These values are normalized and aggregated to form a feature vector that describes the user and is fed as input to the variational autoencoder network.
Variational autoencoder
The variational autoencoder (VAE) network is a core part of the proposed AI-based diet recommendation method and comprises two main components, namely the encoder and the decoder. In the context of meal plan recommendation, the goal of the VAE network is to develop a probabilistic generative model of data and transform the input (i.e., user profile) into a more powerful and discriminative feature representation that lies in a latent space. The new latent space representation is capable of capturing meaningful and informative features about the user’s dietary requirements, which can then be used to generate personalized meal plans. The use of the latent space to model the input contributes significantly to the explainability of the proposed method as it allows the formation of clusters of users with similar nutritional needs. The architecture of the VAE is depicted in Fig. 2.
The primary function of the encoder is to map the input vector (i.e., user profile) into a new more powerful and discriminative feature representation that lies in a latent space. This step is critical as the quality of the representation in the latent space directly impacts the efficacy of the generated meal plans. Given the user profile vector \(\textbfx = (x_1, x_2, \dots , x_u) \in \textrmR^u\), the encoder employs a fully connected layer to map the vector into a new feature vector \(\mathbf x’ = f(\textbfx)\). Then, the new feature vector \(\mathbf x’\) is mapped into a compact and structured representation, i.e., the latent space. To construct this latent space of the user profiles, two fully connected layers are employed to generate the mean \(\mu = f_\mathbf \varvec\mu (\mathbf x’) ,\mu \in \textrmR^d\) (where d is the size of the latent space) and the standard deviation \(\log (\varvec\sigma ^2) = f_\sigma (\mathbf x’) , \sigma \in \textrmR^d\) vectors of the multivariate Gaussian distribution from the feature vector \(\mathbf x’\), where \(f_\mu \) and \(f_\sigma \) denote the fully connected layers responsible for computing the mean and standard deviation vectors of a multivariate Gaussian distribution, respectively. This distribution comprises the latent space that can better model the input user profile vectors. As a result, each dimension in the latent space effectively captures changes in the users’ nutritional needs, dietary requirements and overall health. In addition, in the latent space, users with similar profiles and thus similar nutritional needs are closer to each other and far away from users with significantly different profiles. Such a modelling enables the proposed AI method to improve its explainability by justifying its decisions through a collaborative filtering mechanism (i.e., similar users are provided with similar recommendations).
Through the well-known reparameterization trick38, a latent vector \(\textbfz = \mu + \sigma \odot \varepsilon \) is computed from the multivariate Gaussian distribution \(\mathcal N(\mu ,\sigma )\), where \(\varepsilon \sim \mathcal N(0,1)\) is a random value sampled from a standard Gaussian distribution. Once the descriptive latent representation of the input has been created via the encoder, the responsibility of the decoder is to transform the latent vector \(\textbfz\) into a personalized daily meal plan. The use of recurrent neural networks is motivated by its proven ability to handle sequences efficiently, making it ideal for generating a series of 6 meals for a single day (i.e., breakfast, morning snack, lunch, afternoon snack, dinner and supper). To this end, the decoder uses the Gated Recurrent Unit (GRU) module to handle the generation of a sequence of meals efficiently. The GRU takes as input the latent vector \(\textbfz\) and generates the daily meal plan \(\hat\textbfy(t), ~t=1\dots 6\) as follows:
$$\beginaligned \textbfh(t)&= {\left\ \beginarrayll \text GRU(\textbfz) & \text for t=1 \\ \text GRU(\textbfh(t-1)) & \text for t>1 \endarray\right. \endaligned$$
(1)
where \(\textbfh(t)\) is the hidden state at time t, considering the meals as a temporal sequence spanning from breakfast to supper. The first input to the GRU at time \(t=1\) is the latent vector \(\textbfz\), while for the next timesteps (i.e., \(t>1\)) the previous hidden state \(\textbfh(t-1)\) is fed to the GRU. The predicted meal classes \(\hat\textbfy(t)\) are finally computed as:
$$\beginaligned \textbfo(t)&= \text softmax(f_m(\textbfh(t))),~~ t=[1,6] \endaligned$$
(2)
$$\beginaligned \hat\textbfy(t)&= \arg \max _c(\textbfo(t)),~~~~~~~~~~ t=[1,6] \endaligned$$
(3)
where \(f_m\) is the classifier (i.e., fully connected layer) and \(\mathbf o(t)\) is the output class probabilities at meal time t. The most probable class for a meal is identified by a \(\max \) operation on all class probabilities c as shown in Eq. 3. Two additional fully connected layers are used to predict the total energy \(\hatEI\) and the nutrient values \(\hatn\) of the predicted daily meal plan, which are computed as:
$$\beginaligned \hatEI&= \sum _t=1^Tf_EI(\textbfh(t)) \endaligned$$
(4)
$$\beginaligned \hatn&= \sum _t=1^T f_nutr(\textbfh(t)) \endaligned$$
(5)
where \(f_EI\) is the fully connected layer that predicts the calories of the meal plan and \(f_nutr\) predicts the macronutrients of the meal plan.
User profile
The user profile comprises the only input to the proposed AI-based diet recommendation method and it is crucial for the creation of valid personalized nutritional advice that adheres to user’s needs and nutritional guidelines. The user profile holds important anthropometric measurements and information on the physical activity status and medical condition of a user. More specifically, the profile consists of the weight, the height, the basal metabolic rate (BMR), the age, the body mass index (BMI), the targeted energy intake, the physical activity level (PAL) and the existence or not of cardiovascular disease, type-2 diabetes (T2D) and iron deficiency. These values are normalized and aggregated to form a feature vector that describes the user and is fed as input to the variational autoencoder network.
Loss functions
A novel set of loss functions are proposed to guide the training of the proposed network towards recommending accurate and personalized meal plans. More specifically, the loss functions aim to penalize deviations of the proposed meal plans from the nutritional requirements (i.e., energy and macronutrient intake) defined by the well-established EFSA17,18,19 and WHO20 guidelines for the specific user profile. In this way, the proposed deep network is guided towards providing personalized nutritional advice that satisfy the user needs based on their anthropometric features and medical conditions, thus aligning the proposed AI-based diet recommendation system with the principles of AI trustworthiness.
At first, a macronutrient penalty loss \(L_\text macro\) is used to minimize the difference between the nutritional content of the predicted meal plan and the nutritional rules and guidelines.
$$\beginaligned L_\text macro = \frac1N\sum _i=1^N \left( |min\_val(i)- \hatn)| + |max\_val(i) – \hatn|\right) , \endaligned$$
(6)
In Eq. 6, N is the number of macronutrients (i.e., protein, carbohydrates, fat and saturated fat acids (SFA) and \(min\_val(i)\) and \(max\_val(i)\) is the minimum and maximum suggested values for each nutrient i, since in the nutritional rules the recommended macronutrient intake is defined in ranges. The goal of the macronutrient penalty loss is to align the meal plan proposed by the AI-based diet recommendation system with the nutritional requirements of the user based on their profile. A second loss term, named energy intake loss \(L_EI\), is also proposed to calculate deviations, in the form of mean squared error, between the predicted caloric energy intake \(\hatEI\) of the recommended meal plan and the appropriate energy intake EI based on the user profile.
$$\beginaligned L_\text EI = \frac1N \sum _i=1^N (EI – \hatEI)^2 \endaligned$$
(7)
where the personalized target daily energy intake is calculated based on the factorial approach for computing total energy expenditure39 as:
$$\beginaligned EI = \left\ \beginarraylr BMR*PAL+D, & BMI\le 18.5\\ BMR*PAL, & 18.5< BMI < 25\\ BMR*PAL-D,& 25\le BMI \endarray\right\ \endaligned$$
(8)
In Eq. 8, we consider a parameter D that is used to increase or decrease the target energy intake and assist users with too small or too high BMI achieve the goal of gaining or losing weight. The goal of the energy intake loss is to guide the proposed AI-based diet recommendation method towards suggesting accurate meal plans that satisfy a user’s energy requirements. The losses in Eqs. 6, 7 ensure that the computed meal plans are of high accuracy and comply with the nutritional and energy intake guidelines.
Apart from the aforementioned loss functions, there are two additional losses that are employed to guide the network towards the better modelling of the input space and the compliance with ground truth labels (i.e., meals), respectively. The Kullback–Leibler Divergence (KLD) is employed in order to train the encoder to produce a distribution in the latent space that closely matches a desired distribution, typically a standard Gaussian. This is done to ensure that the latent space is well-structured and can be effectively sampled during the generative phase of the VAE for a user profile. This loss is computed as:
$$\beginaligned L_\text KLD = -\frac12 \sum _j=1^J (1 + \log ((\sigma _j)^2) – (\mu _j)^2 – (\sigma _j)^2) \endaligned$$
(9)
where J is the total number of dimensions in the latent space, \(\sigma _j\) represents the standard deviation of the j-th dimension of the learned latent variable distribution and \(\mu _j\) represents the mean of the j-th dimension of the learned latent variable distribution. \(L_\text KLD\) aims to distribute all latent space encodings for all inputs evenly around the center of the latent space. In this way, the embeddings are as close as possible to each other while still being distinct, allowing smooth interpolation and enabling the generation of new samples.
The last loss function is the cross entropy loss \(L_MC\) that calculates the differences between the output class probabilities and the target meal classes that are provided by the training dataset. This loss function ensures that the meal classifier predicts personalized meals close to the ground truth data and is calculated as:
$$\beginaligned L_MC = -\sum _t=1^T=6\left( \sum _c=1^My_o_t,c\log (p_o_t,c)\right) \endaligned$$
(10)
where M is the total number of different meals, \(y_o_t,c\) indicates whether the class label c is the correct classification for observation \(o_t\) and \(p_o_t,c\) is the probability of class c for the output \(o_t\).
Finally, the total loss L for the proposed diet recommendation method is defined as:
$$\beginaligned L = L_MC + L_\text KLD + L_\text EI + L_\text macro \endaligned$$
(11)
The final loss function aims to structure the latent space in such a way that allows similar user profiles to be close to each other in the latent space, while dissimilar user profiles to be located far from each other, thus enabling the formation of user groups or clusters. In addition, these losses contribute significantly to the explainability of the proposed diet recommendation method by clarifying why two users have been provided with similar or totally different meal plans.

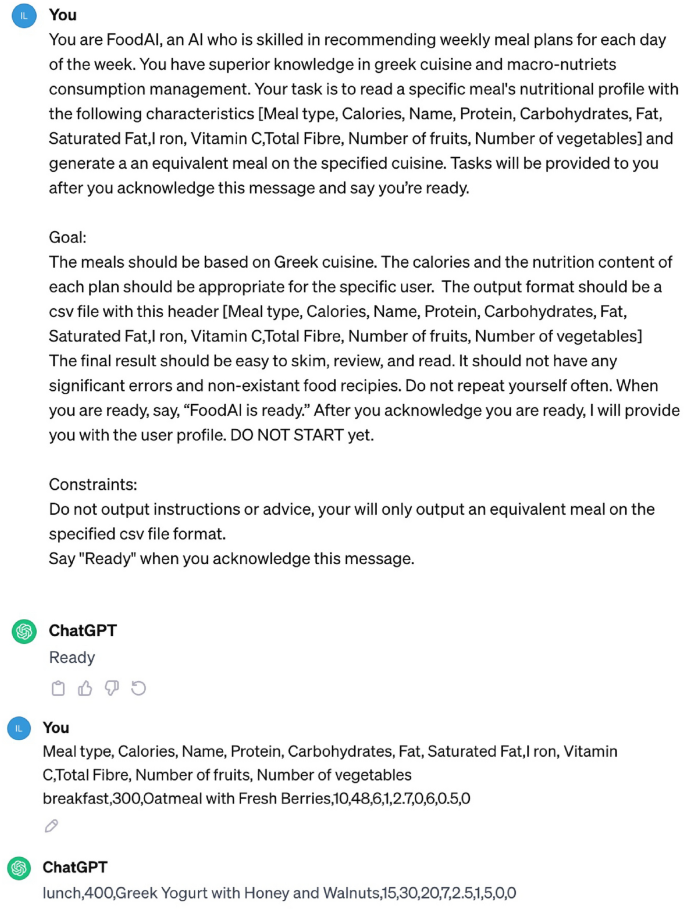
Example of the equivalent meal generation process from ChatGPT.
Meal plan generation
For the creation of the daily meal plan, the decoder runs for 6 timesteps to generate 6 daily meals from each category (i.e., breakfast, morning snack, lunch, afternoon snack, dinner and supper). This output represents the probabilities assigned by the decoder for each meal type and for each meal category and the meal type with the highest probability is selected as the optimal one for the corresponding meal category, according to Eqs. 2, 3. For generating a weekly meal plan, the aforementioned process of daily meal plan generation is repeated 7 times (i.e., one daily meal plan for each day of the week) by sampling different latent vectors from the variational distribution. Moreover, a masking strategy is employed to the output probabilities to ensure meal variation and prevent the VAE from producing similar meal plans every day. The goal of this masking procedure is to keep track of meals selected in previous days of the week and achieve meal diversity. An increased meal diversity can make a meal plan more balanced through the inclusion of various food groups and more attractive and enjoyable for the user, thus increasing the adherence of the user to the recommended meal plan.
Optimizer
The optimizer is the final component of the proposed AI-based diet recommendation method that aims to ensure that the energy intake of the recommended daily meal plan satisfies the user’s energy requirements. This component enhances the accuracy of the proposed method since mismatched energy intake can lead to a plethora of health issues, from weight gain to malnutrition. The optimizer layer acts as a regulatory system, making real-time adjustments to the meal portions based on the targeted energy intake EI. The goal of the optimizer is to match the energy intake of the proposed meal plan \(\hatEI\) to the targeted energy intake of the user. To achieve this, the optimizer changes the meals portions mp in order to zero out the caloric difference of the energy intake of the predicted meal plan and the targeted energy intake of the user. This is done by calculating the percentage of the difference d as follows:
$$\beginaligned d = \fracEI – \hatEI\hatEI \endaligned$$
(12)
Finally, the new meal portions \(mp’\) are changed as:
$$\beginaligned mp’ = d*mp+mp \endaligned$$
(13)
This adjustment ensures that the users consume appropriate meal quantities that correspond to the targeted energy intake and macronutrients of the users based on their personal characteristics and health condition, thus improving the accuracy of the proposed diet recommendation method.
Equivalent meals with ChatGPT
Current diet recommendation systems face an inherent limitation of relying on meal databases with a finite set of meals, meals with incomplete nutritional information or meals generated for specific populations for their training and evaluation40,41. As a result, such systems demonstrate limited ability in providing accurate, reliable and diverse personalized dietary advice. To overcome the aforementioned limitation of diet recommendation systems, this work adopts ChatGPT to expand the meal database of the proposed method in a way that is no longer restricted by its size or the user group that is applied to. In this way, the proposed method leverages the ability of LLMs to acquire information from the web in order to build a large meal database for performing highly accurate meal recommendations for different population groups.
To achieve this, ChatGPT is utilized and instructed to generate meals with similar nutritional profiles and calories. More specifically, an initial standardized query is fed to ChatGPT, which describes the process and instructs it to acknowledge this specific task. By presenting ChatGPT as “FoodAI,” an AI system that is proficient at recommending meals and knowledgeable about many world cuisines, the equivalent meal recommendation process is initiated. ChatGPT is taught to acknowledge the task by saying, “FoodAI is ready”, making sure it is aware of the objectives and limitations before moving forward. Then for every meal in our database, a query with the meal ingredients and nutrition facts is fed to the model. Finally, ChatGPT scans its knowledge base to find dishes from these cuisines that share similarities in ingredients, nutrition facts and calories with the queried meal. The returned meals are parsed and mapped to our meal structure, ensuring compatibility with the rest of our recommendation system. The output is required to be structured like a Comma Separated Values (CSV) file and includes the following headers: Meal name, Meal type, Calories, Protein, Carbohydrates, Fat, Saturated Fat, Iron, Vitamin C, Fibre, Number of fruits and Number of vegetables. An example of this query is given in Fig. 3.

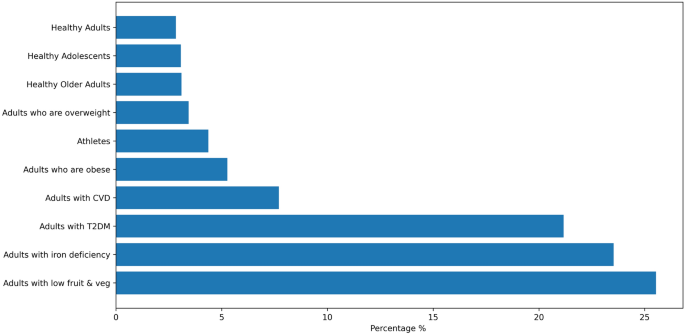
Distribution of 3000 virtual user profiles per user group.
link